
Большинство предприятий в течение многих десятилетий используют MySQL в качестве реляционной СУБД. В их распоряжении находится большое количество данных, используемых либо для транзакций, либо для анализа собираемых и генерируемых данных, и именно здесь как раз и должны быть внедрены аналитические инструменты больших данных (Big Data).
Это теперь стало возможным с интеграцией MySQL с Hadoop. С помощью Hadoop данные можно хранить в подсистеме распределенного хранения, и вы также имеете возможность реализовать кластер Hadoop для распределенной аналитической подсистемы с целью анализа больших данных. Вычислительная среда Hadoop является наиболее предпочтительной в силу ее массивной параллельной обработки и мощных вычислений. С объединением MySQL и Hadoop теперь стало возможным получать аналитику в режиме реального времени, где Hadoop может хранить данные и работать параллельно с MySQL, чтобы показывать конечные результаты в режиме реального времени; это помогает обратиться ко многим случаям использования наподобие информации ГИС. Ранее мы познакомились с жизненным циклом больших данных, где данные могут преобразовываться для получения аналитических результатов. Давайте посмотрим, как MySQL вписывается в этот жизненный цикл.
Следующая ниже схема иллюстрирует то, как MySQL 8 накладывается на каждый из четырех этапов жизненного цикла больших данных:
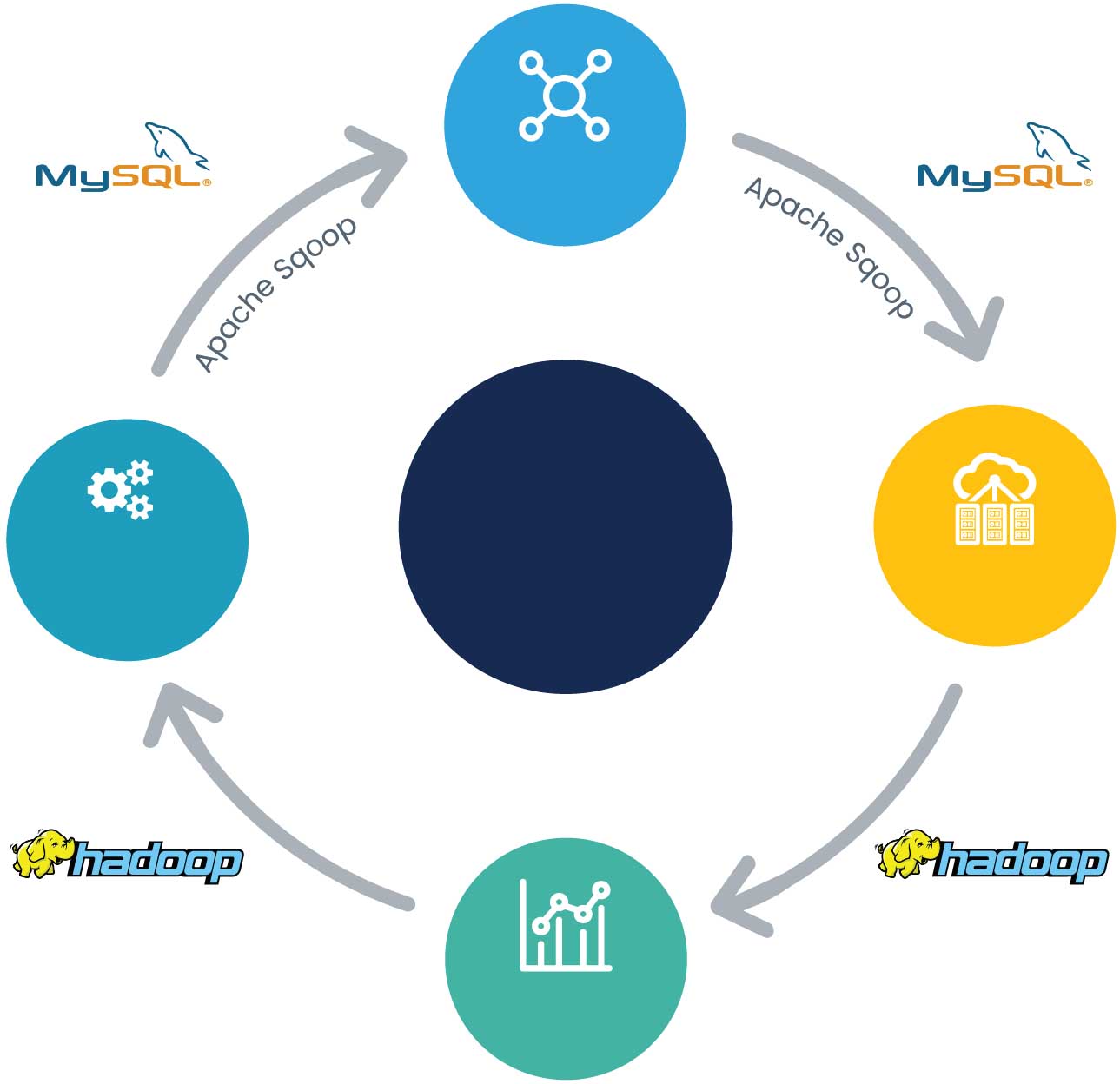
Получение данных в MySQL
С ростом объема и скорости данных становится трудно передавать данные в MySQL с оптимальной производительностью. Чтобы избежать этого, Oracle разработала API NoSQL для хранения данных в подсистеме хранения данных InnoDB. Она не делает никакого анализа и оптимизации SQL, следовательно, данные ключ- значение могут напрямую записываться в таблицы MySQL с высокоскоростными транзакционными откликами без ущерба для гарантий ACID-совместимости. Подсистема MySQL Cluster также поддерживает различные API NoSQL для Node. js, Java, JPA, HTTP/REST и C++. Все это мы рассмотрим подробно позже в этой книге, однако мы должны иметь в виду, что с помощью API NoSQL мы также можем активировать более быструю обработку данных и транзакций в MySQL.
Организация данных в Hadoop
Следующим шагом является организация данных в файловой системе Hadoop, после того как данные были получены и загружены в MySQL. Большие данные требуют некоторой обработки для получения результатов анализа, где Hadoop используется для выполнения высокопараллельной обработки. Hadoop также является масштабируемой распределенной платформой и мощным средством с точки зрения вычислений. Здесь данные консолидируются из различных источников для аналитической обработки. Для передачи данных между таблицами MySQL в HDFS будет использоваться инструмент Apache Sqoop.
Аналитическая обработка данных
Теперь пришло время для анализа данных! Это фаза, где данные MySQL будут обработаны, используя алгоритм Hadoop MapReduce. Чтобы получить аналогичные аналитические результаты, мы можем использовать другие инструменты анализа, такие как Apache Hive или Apache Pig. Мы также можем выполнить собственный анализ, который может быть реализован на Hadoop, возвратив набор результатов с проанализированными и обработанными данными.
Результаты анализа
Результаты, которые были проанализированы в наших предыдущих фазах, загружаются обратно в MySQL; это может быть сделано с помощью Apache Sqoop. Теперь MySQL имеет результат анализа, который может использоваться для инструментов бизнес-аналитики, таких как Oracle BI, Jasper Soft, Talend и т. д., или другими традиционными способами, используя веб-приложения, которые могут формировать различные аналитические отчеты и при необходимости выполнять различные виды обработки в режиме реального времени.
Именно так MySQL легко вписывается в решение по обработке больших данных (Big Data). Эта архитектура позволяет структурированным базам данных выполнять анализ больших данных. Как этого достичь, мы обсудим в последующих статьях, в которых рассматривается несколько решений реальных задач, где мы широко обсуждаем применения MySQL 8 и решения бизнес-задач, связанных с генерированием ценностей из данных.
Резюме
В этой главе мы рассмотрели большие данные и их значение в различных отраслях. Мы также рассмотрели различные сегменты больших данных и их фазы жизненного цикла, включая сбор, хранение, анализ и управление. Мы обсудили структурированные базы данных и почему для больших данных нам нужна структурированная база данных. Мы рассмотрели основные функциональные средства реляционной СУБД MySQL и изучили недавно добавленные в MySQL 8 функциональные средства. Затем мы обсудили основные преимущества использования MySQL и узнали, как установить MySQL 8 в системе Linux с помощью пакета RPM. Наконец, мы разобрались в том, как СУБД MySQL может использоваться в анализе больших данных и как она может вписываться в фазы жизненного цикла больших данных с помощью Hadoop и Apache Sqoop.
В следующей статье вы изучите различные методы запросов в MySQL 8, включая соединения и агрегирования данных.